Local LLM spam classifier — model shootout
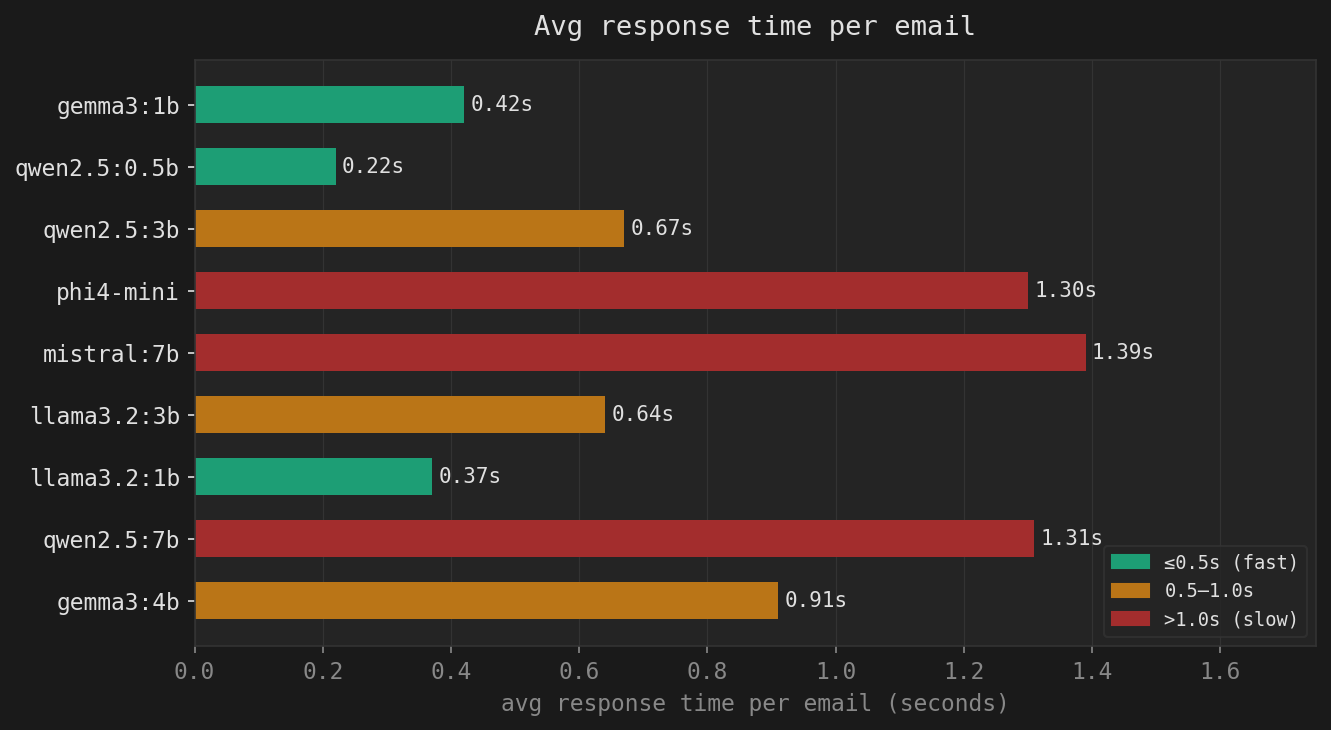
We tested 9 local LLM models as spam classifiers on an AMD EPYC 4545P running Ollama. Here’s what we found. After setting up the SpamAssassin + Ollama integration (see the previous post), the obvious next question was: is qwen2.5:7b actually the best choice, or did we just get lucky picking it first? So we ran … Read more
