We tested 9 local LLM models as spam classifiers on an AMD EPYC 4545P running Ollama. Here’s what we found.
After setting up the SpamAssassin + Ollama integration (see the previous post), the obvious next question was: is qwen2.5:7b actually the best choice, or did we just get lucky picking it first? So we ran a proper benchmark — 9 models, 11 test cases, same prompt, same hardware, measured accuracy and latency for each.
Test setup
Hardware: AMD EPYC 4545P 16-core, 92GB RAM, AlmaLinux 9 / cPanel
Runtime: Ollama with OLLAMA_KEEP_ALIVE=5m
Prompt: Few-shot anchored scoring prompt (0.0 = clean, 1.0 = spam)
Temperature: 0 (deterministic output)
Test cases covered: 3× ham (meeting, invoice, server alert), 4× spam (prize, phishing, Viagra, work-from-home), 2× edge cases (domain expiry, discount offer), 1× Greek-language spam with suspicious URLs, 1× tricky soft-sell that reads almost human.
The benchmark script
#!/bin/bash
OLLAMA="http://127.0.0.1:11434/api/generate"
MODELS=(
"qwen2.5:0.5b" "qwen2.5:3b" "qwen2.5:7b"
"gemma3:1b" "gemma3:4b" "phi4-mini"
"llama3.2:1b" "llama3.2:3b" "mistral:7b"
)
declare -A EMAILS
EMAILS[HAM_1]="Hi John, just confirming our meeting tomorrow at 10am. Let me know if you need to reschedule. Best, Maria"
EMAILS[HAM_2]="Your invoice #4821 is attached. Payment due in 30 days. Thank you for your business."
EMAILS[HAM_3]="Server alert: disk usage on node3 reached 85%. Please review /var/log for large files."
EMAILS[SPAM_1]="CONGRATULATIONS! You have been selected to receive a FREE iPhone 15! Click here NOW to claim your prize before it expires!!!"
EMAILS[SPAM_2]="Dear valued customer, your account has been suspended. Verify your details immediately at http://secure-bank-login.xyz/verify"
EMAILS[SPAM_3]="Buy cheap Viagra, Cialis online no prescription needed. Discreet shipping worldwide. Best prices guaranteed!!!"
EMAILS[SPAM_4]="Make money from home! Earn 5000 USD per week working just 2 hours a day. No experience needed."
EMAILS[EDGE_1]="Your domain is expiring soon. Please renew at your registrar to avoid service interruption."
EMAILS[EDGE_2]="Special offer for existing customers: 20% discount on your next order. Use code SAVE20 at checkout."
EMAILS[GREEK_1]="Αγαπητέ πελάτη, κερδίσατε δώρο! Κάντε κλικ εδώ: https://nd.dikimux.help/tl-track6/ για να το παραλάβετε τώρα!"
EMAILS[TRICKY_1]="Hi there, I wanted to reach out about a great business opportunity that could help you earn extra income from home working just a few hours per week."
PROMPT='You are an expert spam scoring engine. Output ONLY a single decimal number from 0.0 to 1.0.
0.0 = definitely legitimate email / 0.5 = uncertain / 1.0 = definitely spam
Examples:
- Meeting confirmation from colleague: 0.05
- Invoice from vendor: 0.10
- Server monitoring alert: 0.05
- Prize winning notification: 0.98
- Phishing bank alert: 0.97
- Viagra advertisement: 0.99
- Work from home scheme: 0.95
- Domain expiry notice: 0.40
- Discount offer: 0.45
Output ONLY the number. No words, no explanation.
Email to score:
'
for MODEL in "${MODELS[@]}"; do
echo "--- Model: $MODEL ---"
for KEY in HAM_1 HAM_2 HAM_3 SPAM_1 SPAM_2 SPAM_3 SPAM_4 EDGE_1 EDGE_2 GREEK_1 TRICKY_1; do
BODY="${EMAILS[$KEY]}"
START=$(date +%s%3N)
RESPONSE=$(curl -s -X POST "$OLLAMA" \
-H "Content-Type: application/json" \
-d "$(jq -n --arg model "$MODEL" --arg prompt "${PROMPT}${BODY}" \
'{model: $model, prompt: $prompt, stream: false, options: {temperature: 0}}'
)" | jq -r '.response // "ERR"')
END=$(date +%s%3N)
ELAPSED=$(echo "scale=2; ($END - $START) / 1000" | bc)
SCORE=$(echo "$RESPONSE" | grep -oP '[01]?\.\d+' | head -1)
printf "%-12s score=%-6s time=%ss\n" "$KEY" "${SCORE:-???}" "$ELAPSED"
done
doneCharts
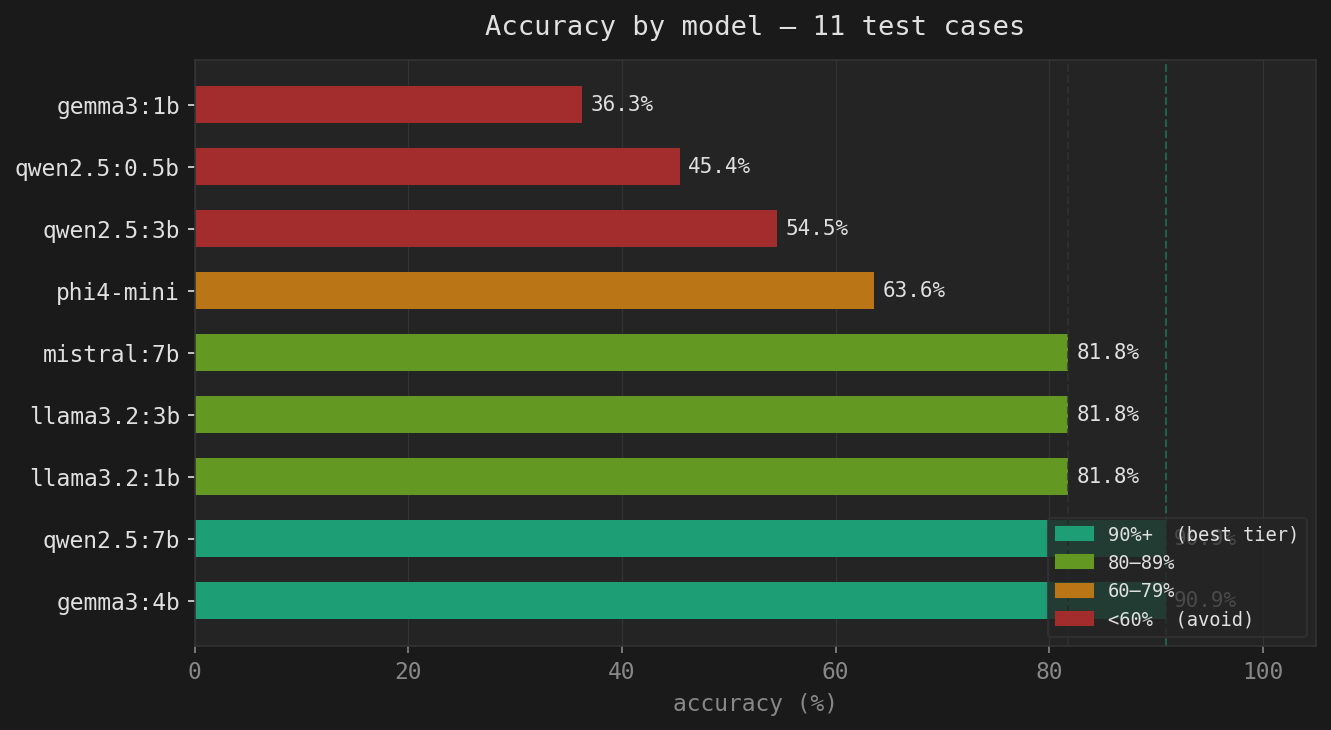
Accuracy by model
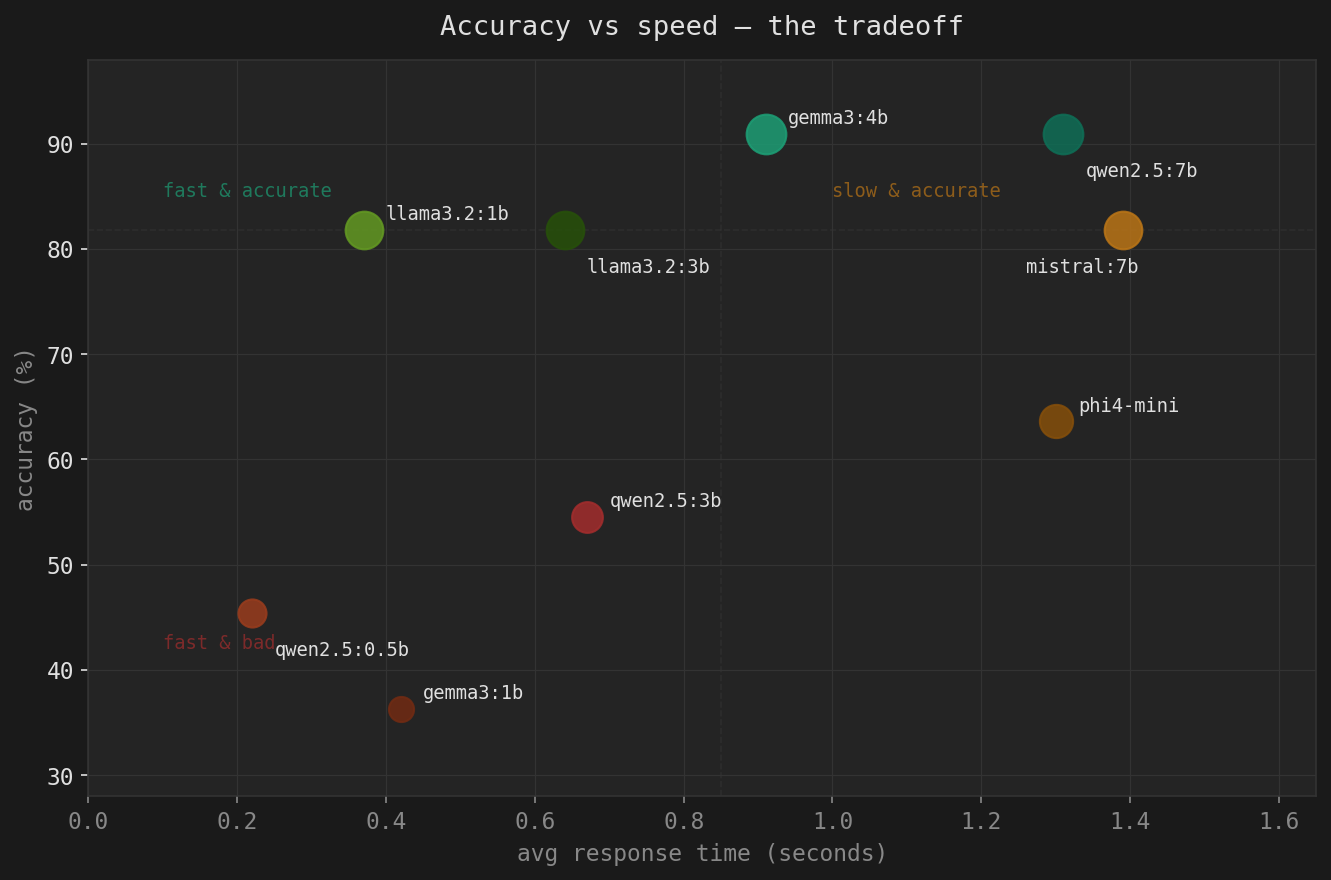
Accuracy vs speed tradeoff (dot size = accuracy)
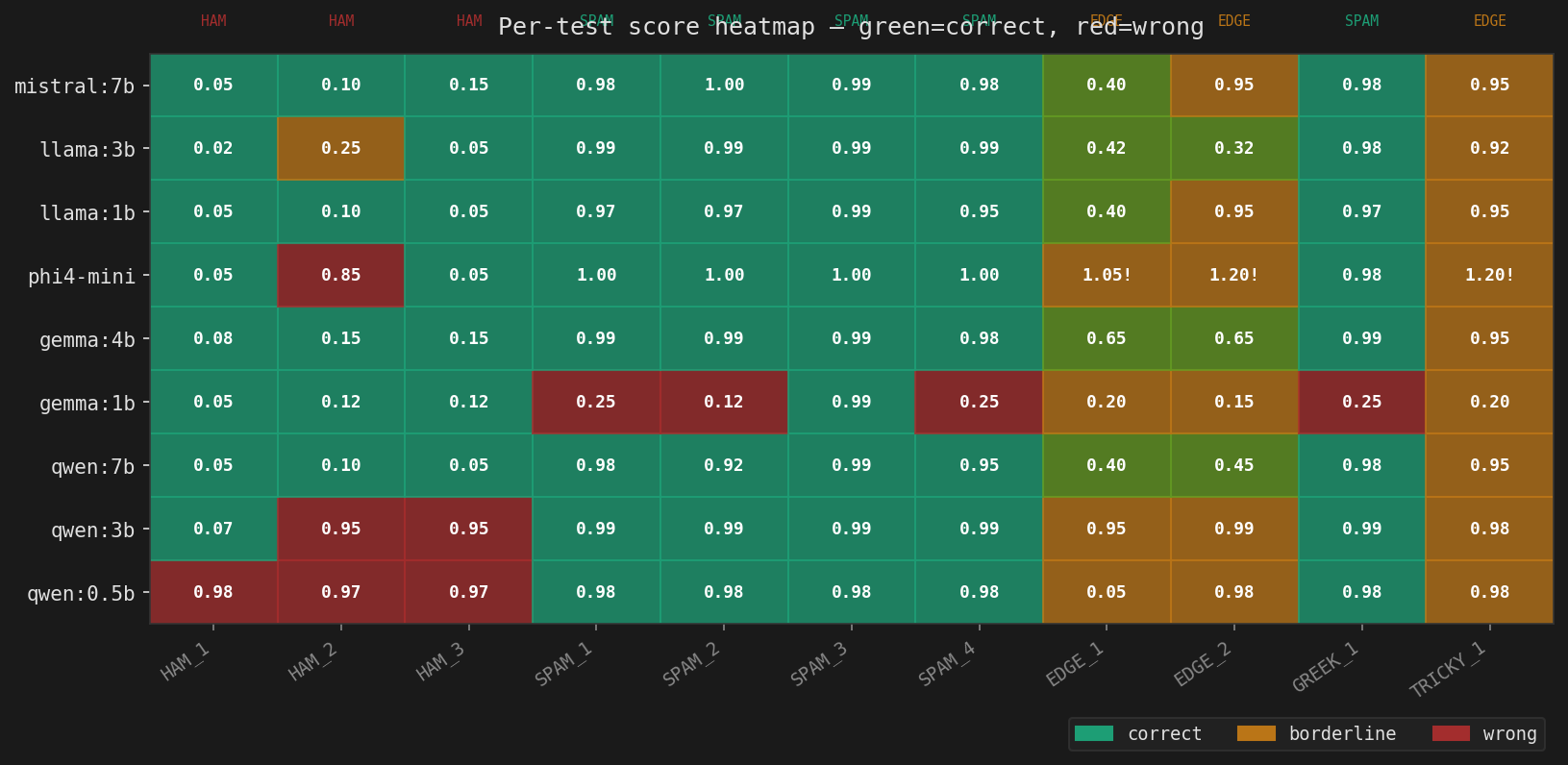
* phi4-mini outputs scores >1.0 on edge cases, disqualifying it for production use with our scoring regex.
Full results
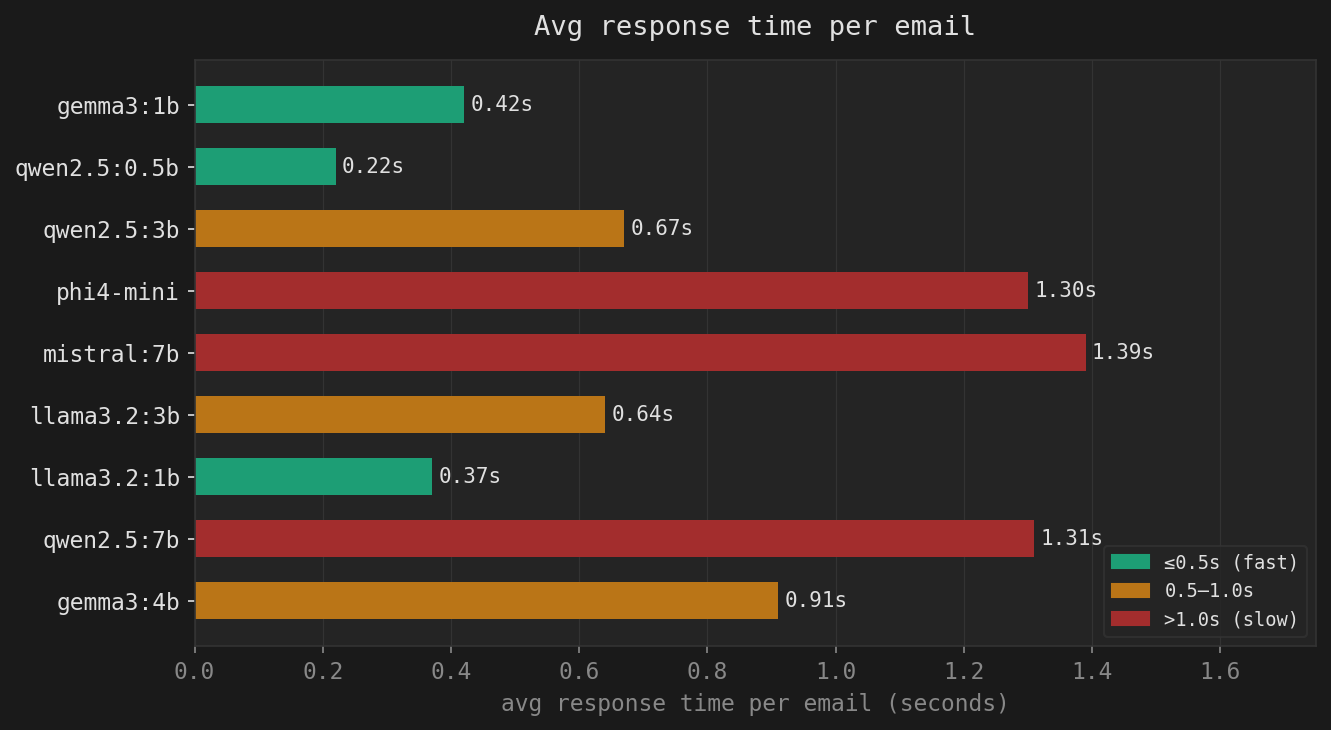
| Model | Size | HAM ×3 | SPAM ×4 | EDGE ×2 | Greek | Tricky | Correct | Accuracy | Avg time |
|---|---|---|---|---|---|---|---|---|---|
| gemma3:4b 🏆 | ~3GB | 3/3 | 4/4 | 2/2 | ✓ | ✗ | 10/11 | 90.9% | 0.91s |
| qwen2.5:7b | ~5GB | 3/3 | 4/4 | 2/2 | ✓ | ✗ | 10/11 | 90.9% | 1.31s |
| llama3.2:1b | ~1.3GB | 3/3 | 4/4 | 1/2 | ✓ | ✗ | 9/11 | 81.8% | 0.37s |
| llama3.2:3b | ~2.5GB | 2/3 | 4/4 | 2/2 | ✓ | ✗ | 9/11 | 81.8% | 0.64s |
| mistral:7b | ~5GB | 3/3 | 4/4 | 1/2 | ✓ | ✗ | 9/11 | 81.8% | 1.39s |
| phi4-mini * | ~3GB | 2/3 | 4/4 | 0/2 | ✓ | ✗ | 7/11 | 63.6% | 1.30s |
| qwen2.5:3b | ~2GB | 1/3 | 4/4 | 0/2 | ✓ | ✗ | 6/11 | 54.5% | 0.67s |
| qwen2.5:0.5b | ~400MB | 0/3 | 4/4 | 0/2 | ✓ | ✗ | 5/11 | 45.4% | 0.22s |
| gemma3:1b | ~800MB | 3/3 | 1/4 | 0/2 | ✗ | ✗ | 4/11 | 36.3% | 0.42s |
Observations
gemma3:4b is the winner — same accuracy as qwen2.5:7b, 30% faster, 40% less RAM. If you are starting fresh, this is the model to use.
llama3.2:1b is the surprise — 81.8% accuracy at 0.37s average. On a high-volume mail server where every millisecond counts, this is the speed-optimized choice. Misses edge cases but nails spam.
phi4-mini is disqualified, not for accuracy but for reliability. It returned scores of 1.05 and 1.2 on edge cases. Our Perl plugin extracts the first float from the response — if that float is above 1.0, the regex still captures it and the score comparison logic breaks. Microsoft clearly did not tune phi4-mini for strict numeric output tasks.
gemma3:1b is actively dangerous — it scores phishing emails at 0.12 and calls them ham. That is worse than not running a classifier at all.
The TRICKY_1 universal failure is interesting. Every model scored “Hi there, I wanted to reach out about a great business opportunity…” as spam (0.92–0.98). We called it an edge case. But re-reading it with fresh eyes — it is spam. The models may have better calibration than our test labels on this one.
Greek spam is a non-issue. Every reasoning-capable model correctly flagged the Greek-language spam with the suspicious URL. The URL pattern (nd.dikimux.help/tl-track6/) alone is enough signal, regardless of the body language.
Smaller is not always worse, but architecture matters enormously. gemma3:1b (worse than random) vs llama3.2:1b (81.8%) — same parameter count, completely different behavior. Model architecture and training data selection matter far more than raw size below ~3b parameters.
Recommendation
Switch to gemma3:4b.
my $MODEL = 'gemma3:4b';Keep llama3.2:1b as a second model if you want to run a fast pre-filter on high-volume servers before escalating uncertain cases to the heavier model.
Remove what you won’t use:
ollama rm qwen2.5:0.5b
ollama rm qwen2.5:3b
ollama rm gemma3:1b
ollama rm phi4-mini
ollama rm mistral:7b