Part of the CFM server security platform. This post covers what kernsec does, how it works, how to use it, and how it relates to the Linux kernel’s proposed Killswitch primitive.
The problem it solves
A stock AlmaLinux or CloudLinux install ships with a running kernel that supports hundreds of subsystems almost no hosting server will ever use: amateur radio protocols, 1980s network stacks, optical disc filesystems, infrared communication, virtual video devices. These subsystems exist in kernel memory, can be autoloaded on first use, and represent real attack surface — many CVEs in the past few years trace directly to one of them.
At the same time, the kernel’s own hardening knobs — a sprawling set of sysctls, boot arguments, and compile-time options documented by the Kernel Self-Protection Project (KSPP) — go untouched on most production systems because applying them correctly without breaking real workloads takes more time than most operators have.
cfm kernsec solves both problems with a single managed component.
Philosophy: audit first, apply explicitly
kernsec never silently mutates a host. The default command, cfm kernsec, opens an interactive TUI (or falls back to text output on non-TTY) that shows the full audit without changing anything. Mutation only happens when you explicitly run cfm kernsec apply.
This is intentional. On a shared hosting server managing hundreds of customer vhosts, a misconfigured sysctl or a blacklisted module that a customer’s process depends on can escalate from “security improvement” to “support ticket” very fast. kernsec shows you what it intends to do first, tells you exactly what each rule affects, and requires explicit confirmation before writing anything.
The same philosophy applies to /etc/fstab: kernsec audits mount options and surfaces what is missing, but it never edits fstab. Mount changes on a live hosting server require operator judgment.
The tier system
Rules are grouped into two tiers.
Tier 1 is safe-everywhere for shared hosting, KVM, and cPanel/CloudLinux stacks. These are the defaults. Every rule in Tier 1 has been validated against the real hosting workload — CloudLinux LVE, CageFS, cPanel jails, PHP-FPM, MySQL, Dovecot, Exim, Postfix.
Tier 2 is server-aggressive and opt-in. These rules either have meaningful blast radius on some workloads or require more operator context. Examples: disabling unprivileged user namespaces (breaks rootless containers), oops=panic (reboots on kernel oops), and panic_on_oops. You enable Tier 2 by setting tier = 2 in /etc/cfm/kernsec.conf.
The tier system is not about whether a hardening measure is correct — all rules are correct. It is about whether the blast radius is bounded without operator context.
What kernsec manages
Sysctls — /etc/sysctl.d/99-cfm-kernsec.conf
kernsec owns and enforces the KSPP sysctl baseline plus a set of CFM extensions. Rules fall into groups:
kspp.kernel — Core KSPP sysctls: kernel.kptr_restrict=2 (hide kernel pointers from userspace), kernel.dmesg_restrict=1 (restrict kernel log to root), kernel.unprivileged_bpf_disabled=1, kernel.randomize_va_space=2, kernel.yama.ptrace_scope=1 (restrict ptrace to direct children), kernel.perf_event_paranoid=3.
kspp.fs — Filesystem hardening: fs.protected_hardlinks=1, fs.protected_symlinks=1, fs.protected_fifos=2, fs.protected_regular=2.
sysctl.mem.exploit — Exploit technique mitigations: vm.mmap_rnd_bits=32 and vm.mmap_rnd_compat_bits=16 (ASLR entropy), kernel.warn_limit=10 and kernel.oops_limit=10 (rate-limit warning/oops spray), fs.suid_dumpable=0 (no core dumps from setuid binaries).
sysctl.kernel.surface — Surface reductions: dev.tty.ldisc_autoload=0 (no automatic TTY line-discipline module loading — closes the n_hdlc-style attack path), kernel.sysrq=0.
sysctl.net.harden — Network hardening: source-route rejection, martian logging, RFC1337 TIME_WAIT fix, broadcast ICMP ignore.
sysctl.net (EXT) — Keys owned by cfm-sysctl-tweaks (the daemon’s imperative TCP tuning): rp_filter, accept_redirects, send_redirects, tcp_syncookies. kernsec audits these but never writes them — ownership is tracked in CFM’s cross-component registry. The audit surfaces EXT with the live value so you can see whether the other component’s intent is actually active.
Tier 2 adds user.max_user_namespaces=0, kernel.unprivileged_userns_clone=0 (kills a major LPE primitive class, but breaks rootless podman, bwrap, and some hosting isolation — skipped automatically when containers or CloudLinux/CageFS are detected), kernel.panic_on_oops=1, and kernel.panic=10.
Boot arguments — bootloader-backend managed
kernsec manages a defined set of cmdline keys across three bootloader backends (BLS/grubby, legacy GRUB, Proxmox). It strips stale instances of its own managed keys before appending the desired set, and never touches operator-provided arguments outside its managed set.
kspp.boot (Tier 1):
slab_nomerge— prevents slab cache merging, hardens type-confusion UAF exploitsinit_on_alloc=1— zero pages on allocation, eliminates uninitialized-memory leaks kernel-widepage_alloc.shuffle=1— randomize buddy-allocator freelists, mild ASLR boost for kernel allocationsrandomize_kstack_offset=on— per-syscall kernel-stack randomization, makes ROP/stack-spray harderinitcall_blacklist=algif_aead_init— runtime killswitch for Copy Fail / CVE-2026-31431: blocks the AEAD AF_ALG initialization at boot, preventing the exploit’s send-path primitive from being reachable
boot.bug-detection (Tier 1): kfence.sample_interval=100 — enables low-overhead KFENCE heap corruption detection sampling.
boot.dma (Tier 1): efi=disable_early_pci_dma — disables early pre-IOMMU EFI PCI DMA; skipped automatically on non-EFI hosts.
boot.sidechannel (Tier 1): tsx=off — disables Intel TSX, eliminating the TAA/TSX side-channel surface entirely.
tier2.oops (Tier 2): oops=panic — paired with kernel.panic_on_oops=1, causes the kernel to reboot instead of continuing after memory corruption.
Module blacklists — /etc/modprobe.d/cfm-kernsec.conf
This is where kernsec does the most work per line of config. For each rule, apply writes both a blacklist <module> line (prevents alias-based autoloading) and an install <module> /bin/false line (prevents direct modprobe loads). Two lines because blacklist alone is bypassed by modprobe -f and some alias paths.
The current catalog covers 82 modules across 9 groups:
modules.recent_cves — Modules that have been directly exploited or have no conceivable server use case: ksmbd (in-kernel SMB server, multiple LPE CVEs 2023–2025), n_hdlc (the n_hdlc LPE class), vivid (virtual video driver, frequent CVE/CTF target), watch_queue (Dirty Cred vector), binfmt_aout, nfc, nfcsim, pn533, pn533_usb.
modules.net.legacy — 26 dead network protocols: dccp (multiple LPEs), tipc (cluster IPC LPEs), rds (Oracle-internal reliable datagram), rxrpc (AFS RPC), ax25/netrom/x25/rose (amateur radio protocols, explicitly named in the Linux Killswitch proposal), decnet, econet, ipx (Novell), appletalk, various LLC/SNAP encapsulations, pptp, gtp, can, atm, irda, phonet, caif, caif_socket, hsr.
modules.net.virt — vsock (VMware/QEMU guest↔host virtual sockets — also explicitly named in the Killswitch proposal; skipped when IsKVMHost is detected since KVM hypervisor hosts need it for guest communication).
modules.net.iot — IoT/embedded protocols with no server purpose: 6lowpan, ieee802154, ieee802154_6lowpan.
modules.fs.unused — 17 filesystems no hosting server mounts: cramfs, freevxfs, jffs2, hfs, hfsplus, udf, qnx4, qnx6, omfs, befs, ufs, affs, sysv, nilfs2, gfs2, ocfs2, coda.
modules.fs.container — overlay is blacklisted where containers are not detected. The host profile probe checks for runc/containerd/LXC/podman and auto-skips this rule if any are running.
modules.bus.bluetooth — bluetooth, btusb, bnep, hci_uart. Auto-skipped when Bluetooth hardware is detected via /sys/class/bluetooth.
modules.bus.firewire — firewire-core, -ohci, -net, -sbp2. DMA attack surface; no server use.
modules.bus.thunderbolt — thunderbolt. Auto-skipped when Thunderbolt devices are detected.
modules.bus.misc — joydev, pcspkr, floppy.
modules.sidechannel — intel_rapl_common, intel_rapl_msr. Removes Intel RAPL/Platypus power telemetry side-channel surface (CVE-2020-8694).
modules.crypto_userapi — algif_hash, algif_skcipher, algif_rng, algif_akcipher. Extends the AF_ALG hardening beyond what initcall_blacklist=algif_aead_init covers at boot. Together with the boot arg, this eliminates the entire AF_ALG userspace crypto API surface — all five algif_* socket families.
NFS, CIFS/SMB clients, io_uring, and wifi modules are intentionally not blacklisted. These have legitimate use on real fleet nodes.
Mount audit — report only
kernsec audits four mount points and surfaces missing options, but never edits /etc/fstab:
/tmp— recommendnodev,nosuid,noexec/var/tmp— same/dev/shm— recommendnodev,nosuid,noexec/home— recommendnodev,nosuid(notnoexec— hosting panels need exec on home)
Host profile detection
Before resolving any rule, kernsec probes the host and builds a profile that gates rules which would break real workloads. This runs automatically — operators don’t configure it. Detected signals include:
IsKVMHost— kvm_intel/kvm_amd loaded → don’t blacklist vsockHasContainers— runc/containerd/lxc/podman running → don’t kill user namespaces or overlayHasIPsec—ip xfrm policynon-empty → don’t touch IPsec modulesHasBluetoothHardware—/sys/class/bluetoothnon-empty → keep Bluetooth modulesHasThunderbolt—/sys/bus/thunderbolt/devicesnon-empty → keep thunderboltIsCPanel,HasCloudLinuxLVE,HasCageFS— hosting panel detectionHasKernelCare,HasKsplice— live-patching agents (affects module loading behavior)IsProxmox— Proxmox boot backend selectionHasDKMS— out-of-tree module evidence → conservative on module rules
Rules gated by these signals render as SKIP (host profile: <reason>) in audit output. Operators override per-rule with state = force in kernsec.conf.
Using it
First run
cfm kernsec # TUI on a TTY; text audit otherwise (read-only)
cfm kernsec text # force plain-text output
cfm kernsec preview # show what apply would do
Applying
cfm kernsec init # write /etc/cfm/kernsec.conf with tier=1 if absent
cfm kernsec apply --dry-run # show changes without writing
cfm kernsec apply # interactive: preview + confirmation
cfm kernsec apply --yes # unattended (Ansible, cron)
apply writes files in safe order: managed sysctl drop-in and modprobe file first (reversible), bootloader cmdline update next, then sysctl -w per-key last. Runtime sysctl application is last specifically so a failure in the bootloader step doesn’t leave Tier 2 sysctls (like user.max_user_namespaces=0) active in the running kernel without a persistent file backing them.
Monitoring
cfm kernsec status --check # exits non-zero on any WARN; suitable for cron/Nagios
cfm kernsec status --json # machine-readable, for fleet aggregation
cfm kernsec monitor enable # install systemd drift-check timer
cfm kernsec monitor status # show last timer runs
For fleet status collection:
for h in virgo titan orion rigel mars earth edge; do
echo "=== $h ===" && ssh root@$h cfm kernsec status --json | jq .ok
done
Per-rule overrides
/etc/cfm/kernsec.conf accepts per-rule state overrides without changing the tier. For example, on mars the operator has forced several rules that the host profile would otherwise skip:
tier = 1
[rule "KSEC-BOOT-sidechannel-001"]
state = force # tsx=off — force even on this specific host
[rule "KSEC-MOD-net.legacy-024"]
state = force # phonet
[rule "KSEC-MOD-net.virt-001"]
state = skip # vsock — needed on this KVM host despite IsKVMHost detection
Valid states are default (follow tier), force (apply regardless of host profile), and skip (never apply regardless of tier).
Recovery
cfm kernsec disable --dry-run # preview what disable removes
cfm kernsec disable # persist tier=0, strip managed boot args
cfm kernsec rollback # restore pre-apply bootloader snapshot
rollback uses the .cfm-kernsec.bak snapshots written before each apply. It removes only kernsec-managed cmdline keys — operator-provided args outside the managed set are preserved.
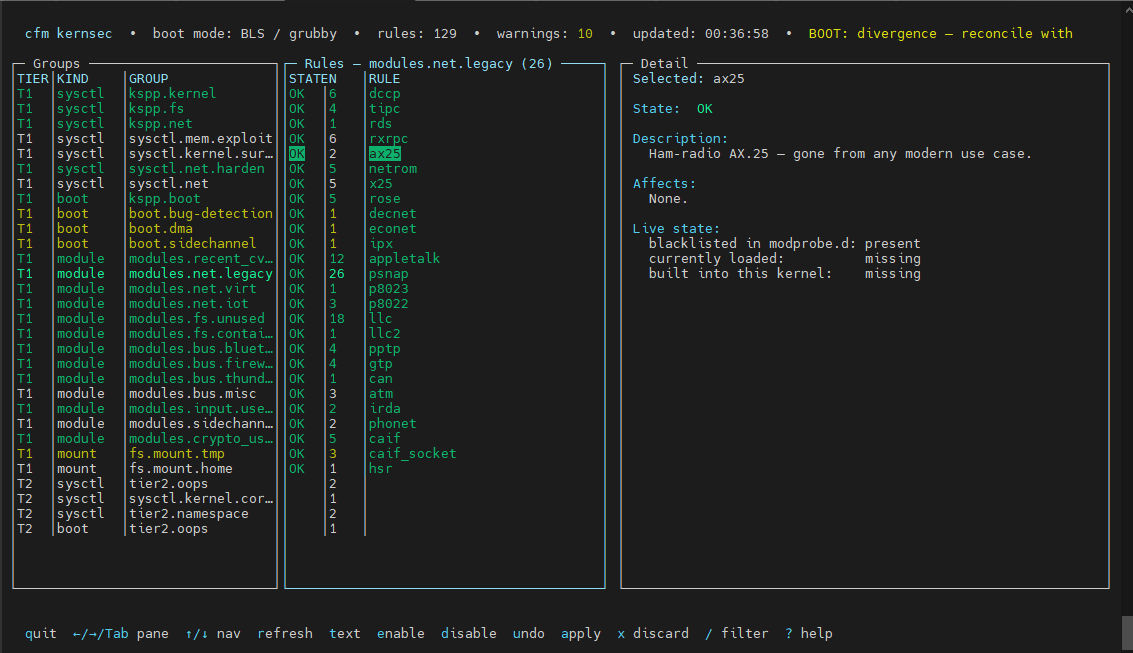
Runtime state output — reading the TUI
The TUI (screenshot above) shows three panes: Groups on the left, Rules in the middle, Detail on the right. The middle pane shows per-rule state:
OK— rule is applied and verified liveWARN— rule is configured but not yet active (reboot required for boot args, or module still loaded)DIFF— sysctl present but with wrong value (drift from another tool)MISSING— expected entry absent from managed fileSKIP— host profile blocks the rule, or the sysctl key/module isn’t exposed by this kernelOFF— operator explicitly disabled (tier below rule’s tier, orstate = skip)DRIFT— active in current boot but missing from next-boot configLOADED— module blacklisted but still loaded; needs reboot orrmmodEXT— key owned by another CFM component; kernsec audits only
The rules: 129 warnings: 10 in the TUI header and the BOOT: divergence — reconcile with notice are the two key signals to watch: warnings mean drift from desired state, divergence means not all kernels have the same managed args applied (common during a kernel update when an old kernel still boots).
The killswitch connection
In May 2026, Linux stable kernel co-maintainer Sasha Levin proposed a feature called Killswitch — a mechanism to make a kernel function return a fixed value without executing its body, as a temporary mitigation while a patch cycle completes. The proposal explicitly names the problem: “when a security issue goes public, fleets stay exposed until a patched kernel is built, distributed, and rebooted into.”
kernsec already implements this philosophy at every layer below the kernel:
Boot-time killswitch — initcall_blacklist=algif_aead_init is, literally, a function-level killswitch applied at kernel init time. When Copy Fail (CVE-2026-31431) dropped with a working exploit before distro kernels were patched, this single boot arg made the vulnerable code path unreachable. kernsec manages, applies, and verifies this automatically.
Module-level killswitch — The install <module> /bin/false pattern is a killswitch for any kernel subsystem that lives in a loadable module. Every rule in modules.recent_cves and modules.net.legacy is a pre-emptive killswitch applied before a CVE drops, removing attack surface that the kernel will never need to load. When ksmbd had its LPE series in 2023–2025, hosts with kernsec deployed were unaffected because the module couldn’t load.
The Killswitch proposal’s named targets vs. kernsec coverage:
| Subsystem | Killswitch proposal | kernsec |
|---|---|---|
| AF_ALG | af_alg_sendmsg engage -EPERM |
initcall_blacklist=algif_aead_init (boot) + algif_* blacklist (module) |
| ksmbd | ksmbd_smb2_read engage -EPERM |
modules.recent_cves blacklist |
| nf_tables | named candidate | intentionally excluded — CFM depends on nf_tables |
| vsock | named candidate | modules.net.virt blacklist (KVM-host gated) |
| ax25 | named candidate | modules.net.legacy blacklist |
Three of the five named Killswitch candidates are already covered by kernsec’s module blacklists. The AF_ALG case is covered at boot time. nf_tables is the only one that can’t be touched without breaking CFM’s own firewall backend.
The key difference is timing: kernsec’s module blacklists are applied proactively at install time, before any CVE is announced. The kernel Killswitch primitive is designed for the reactive case — a zero-day drops, you engage the killswitch before a patch is ready. The two approaches are complementary: kernsec eliminates the surface area that will never be needed; Killswitch handles the residual cases where a needed function turns out to be vulnerable.
What it does not do
kernsec deliberately does not:
- Set
kernel.modules_disabled=1— this is a one-way runtime switch that requires careful late-boot orchestration so cfm and host services can finish loading required modules first. Planned as a follow-up with a proper systemd unit. - Edit
/etc/fstab— mount changes require operator judgment on live hosting servers. - Manage NFS, CIFS, io_uring, or wifi modules — legitimate use exists on fleet nodes.
- Implement Killswitch engage/disengage — the kernel interface doesn’t exist in any distro kernel yet. When it lands in AlmaLinux/CloudLinux kernels, kernsec’s audit layer is designed to surface the state via
cfm kernsec status.
Implementation notes for the technically curious
kernsec is written in Go and lives in internal/kernsec/. The key design points:
Schema-driven rule registry — Every rule is a Go struct (SysctlRule, BootArg, ModuleRule, MountRule) with a stable KSEC-<class>-<group>-<NNN> ID. The resolver joins rules against the host profile and conf overrides to produce per-rule Decision values (Apply / SkipByConf / SkipByTier / SkipByHostProfile). The audit then attaches live probes to each decision.
Atomic file writes with backup — All writes are atomic (write to temp, rename). The first write backs up the original file as <path>.cfm-kernsec.bak. Subsequent writes warn if the file contains lines outside the managed set (operator-edited managed files) without blocking the apply.
Per-key sysctl apply — apply calls sysctl -w key=value per key rather than sysctl -p, so a single rejected key (kernel version mismatch, security module blocking the write) doesn’t stop the rest. Keys not exposed by the running kernel are detected via /proc/sys/<path> existence check and skipped at render time.
Multi-backend boot arg management — Three backends (BLS/grubby, legacy GRUB, Proxmox) with a clean interface. Each backend owns reading and writing the current and next-boot cmdline. The managed key set is authoritative: apply strips any stale instance of a managed key before appending the desired set, preventing accumulation of duplicate args across kernel updates.
Cross-component registry — internal/managedsysctl tracks which CFM component owns which sysctl key. kernsec checks this before writing any key and renders EXT rows for keys owned elsewhere. This prevents two CFM components from writing conflicting values to the same sysctl.