A grounded look at kernel attack surface reduction for production hosting servers — no silver bullets, just honest defense.
The kernel LPE wave of 2025–2026 was a good reminder that most Linux servers are running with more attack surface exposed than they need. Dirty Frag, Copy Fail (CVE-2026-31431), the ksmbd parade, watch_queue, Dirty Cred — most of these exploits hit code paths that a typical hosting, KVM, or cPanel server never legitimately uses. The modules were just… there, loaded by default, waiting.
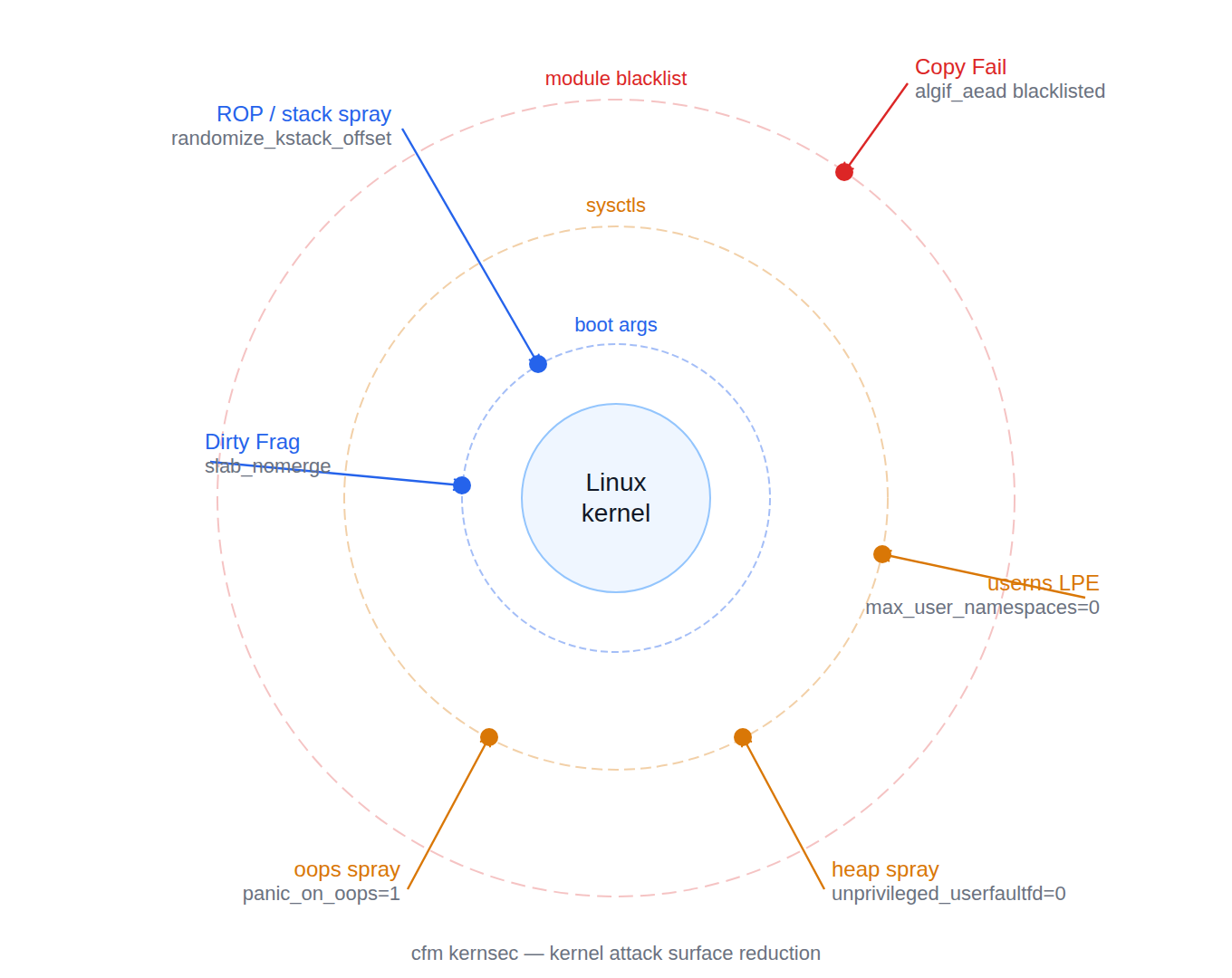
That’s the core insight behind cfm kernsec: not to stop zero-days (nothing does, reliably), but to reduce the number of kernel code paths an attacker can reach at all. Every module that isn’t loaded, every sysctl that closes a primitive, is a dead end they have to work around.
This post explains what we shipped, why each piece matters, and what it concretely would (and wouldn’t) have done against real exploits.
What kernsec is
cfm kernsec is a subsystem of the CFM server security platform. It manages three categories of kernel hardening:
- Boot-time arguments — passed to the kernel at startup via the bootloader (Proxmox/systemd-boot, BLS/grubby, or legacy GRUB — auto-detected)
- Runtime sysctls — written to
/etc/sysctl.d/99-cfm-kernsec.confand applied live - Module blacklists — written to
/etc/modprobe.d/cfm-kernsec.confpreventing load of modules the server has no business using
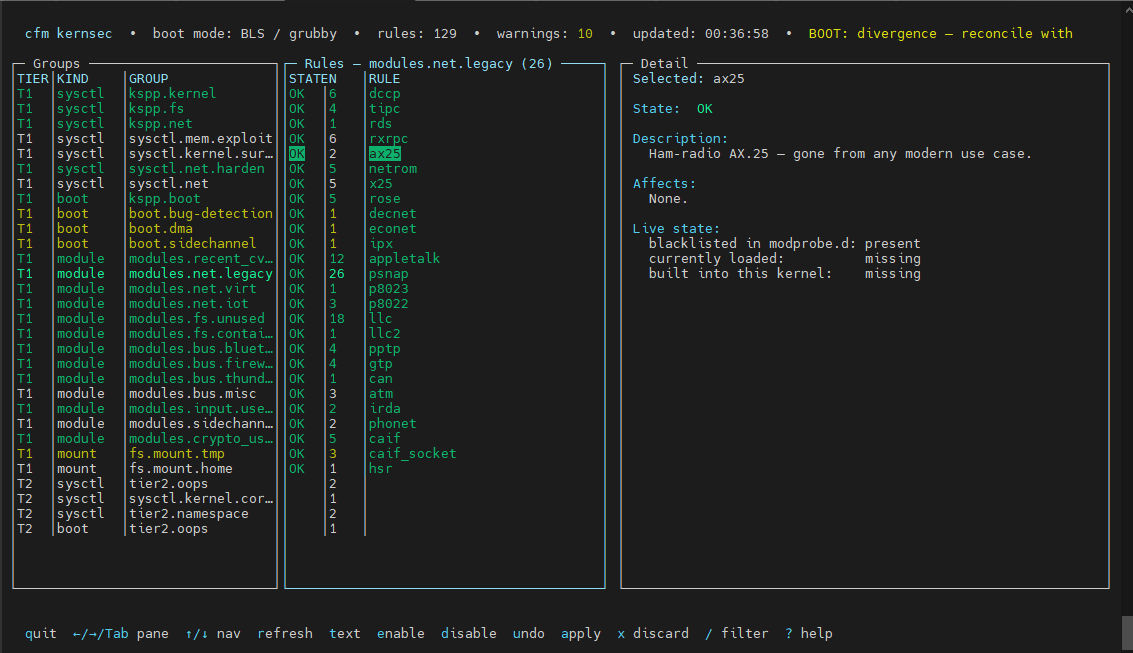
Rules are tiered (Tier 1 safe-by-default, Tier 2 operator-opt-in aggressive), grouped semantically, and each carries a stable ID (KSEC-<class>-<group>-<NNN>). A host-profile probe auto-skips rules that would break real workloads: DKMS hosts don’t get module.sig_enforce=1, container hosts don’t get user.max_user_namespaces=0, kdump hosts keep kexec.
Operators get cfm kernsec status for audit, cfm kernsec preview for a read-only diff, cfm kernsec apply to write everything atomically, and a cfm kernsec monitor systemd timer for daily drift detection.
The rule set derives from the KSPP (Kernel Self Protection Project) server-safe profile, extended with module blacklisting and hosting-specific threat modeling.
The exploit lens: what would have helped, what wouldn’t
Let’s be direct. We’re going to walk through several real exploit classes and say specifically what kernsec does against them — including “nothing useful here.”
Copy Fail / CVE-2026-31431
This is the one we shipped a mitigation for first, before the full kernsec system existed. The exploit reaches the kernel AEAD path via the AF_ALG userspace crypto API (algif_aead). On an unpatched kernel, a local unprivileged user can trigger a use-after-free in that code path and escalate to root.
What kernsec does:
The most direct mitigation is a boot argument:
initcall_blacklist=algif_aead_init
This prevents algif_aead_init() from running during boot, so the AEAD AF_ALG socket type is never registered. The bind syscall fails immediately — exploit has no surface to reach. We verify this with a live AF_ALG bind probe during cfm kernsec status.
Beyond the boot arg, kernsec’s module blacklist goes further. Even if the boot arg is absent or the arg is applied to a future kernel that reorganizes init paths, the modules.crypto_userapi rule group blacklists the entire userspace crypto API family:
blacklist algif_aead
blacklist algif_hash
blacklist algif_skcipher
blacklist algif_rng
blacklist algif_akcipher
install algif_aead /bin/false
install algif_hash /bin/false
# … etc
The install … /bin/false lines are critical: they prevent on-demand module loading even if something tries to pull the module in transitively.
Honest limits: This works for variants that require AF_ALG AEAD access. A Copy Fail variant that finds a different kernel code path for the same underlying UAF — or that exploits a different subsystem entirely — is not stopped here. What we’ve done is close this specific door, not the class.
Dirty Frag
Dirty Frag (part of the broader 2025–2026 heap-manipulation wave) exploits predictable slab behavior to achieve type-confusion across adjacent allocations. The attack depends on being able to predict or control which slab caches objects land in and which free objects are available adjacent to the target.
What kernsec does:
slab_nomerge # boot arg
init_on_alloc=1 # boot arg
page_alloc.shuffle=1 # boot arg
slab_nomerge stops the kernel from merging slab caches that have similar sizes. Without merging, the attacker can’t arrange for a controlled-allocation to land in the same cache as the vulnerable object. This directly degrades the spatial predictability that Dirty Frag-class exploits depend on.
init_on_alloc=1 zeroes all pages and slab objects on allocation. This kills the uninitialized-memory information-leak primitive that many heap exploits need as a first step — without a leak, building a reliable write primitive gets much harder.
page_alloc.shuffle=1 randomizes the buddy-allocator freelist order, adding entropy to kernel allocation addresses. A mild ASLR boost for kernel-space allocations.
Together these raise the cost of reliable heap shaping substantially. They don’t make Dirty Frag impossible; they make it noisier, less reliable, and harder to port across kernel versions reliably.
Also relevant here:
kernel.warn_limit=10
kernel.oops_limit=10
kernel.panic_on_oops=1
Dirty Frag and related exploits sometimes use WARN/oops spraying as a side-channel to understand kernel memory layout. Limiting warns and oopses per boot, and rebooting on oops, removes that oracle — and a rebooted server is a reset exploitation environment.
Unprivileged user namespace LPE (the whole class)
This is currently the most active LPE primitive class in the Linux kernel. A huge fraction of recent local privilege escalation CVEs require unshare(CLONE_NEWUSER) to work — unprivileged user namespaces give an attacker a sandboxed capability context to trigger privileged code paths. The ksmbd bugs, watch_queue, Dirty Cred, and a long list of others all require or are made vastly easier by unprivileged userns.
What kernsec does (Tier 2):
user.max_user_namespaces=0 # KSEC-SCT-namespace-001
kernel.unprivileged_userns_clone=0 # KSEC-SCT-namespace-002 (Debian)
This is the most impactful single setting for LPE defense on a hosting server that doesn’t run containers. Setting user.max_user_namespaces=0 makes unprivileged user namespace creation fail at the syscall level. The exploit literally cannot proceed past unshare(). For a large fraction of the CVEs published in 2024–2026, this is a categorical blocker.
Why it’s Tier 2: The host-profile probe checks for container workloads (rootless podman, bwrap, Docker without the daemon running as root, some cPanel jail variants). If any are detected, the rule is auto-skipped. Operators on dedicated hosting boxes with no container workloads can apply Tier 2 and get real protection. Operators on mixed-use systems have to make the call manually.
userfaultfd heap-spray (UAF primitive enabler)
userfaultfd is a legitimate API for userspace fault handling, but it became notorious as an exploit primitive. Many UAF exploits use it to pause kernel execution at a precise moment — after a free but before the memory is reused — giving the attacker time to spray a controlled allocation into the freed slot. Without userfaultfd, timing-sensitive UAF exploits become far harder to pull off reliably.
What kernsec does:
vm.unprivileged_userfaultfd=0 # KSEC-SCT-mem.exploit-001
This disallows userfaultfd for unprivileged processes. The system call is still available to root and to processes with CAP_SYS_PTRACE. Normal user processes — which is where attacker-controlled code runs — can no longer register fault handlers.
This doesn’t stop UAF exploits. It removes one of their most reliable synchronization primitives. The exploit has to find another way to win the race.
Side-channel attacks on power subsystems (Platypus / CVE-2020-8694)
The Platypus attack used Intel’s RAPL (Running Average Power Limit) interface to infer secret cryptographic material through power consumption measurements. RAPL data is exposed via kernel modules.
What kernsec does:
blacklist intel_rapl_common
blacklist intel_rapl_msr
install intel_rapl_common /bin/false
install intel_rapl_msr /bin/false
Servers don’t need power telemetry for cryptographic workloads. Blacklisting these modules removes the measurement surface entirely. No module means no attack path, regardless of whether a new variant of the side-channel emerges.
n_hdlc and similar legacy tty line disciplines
CVE-2017-2636 (n_hdlc UAF) is an old example but the pattern repeats: obscure kernel subsystems that get loaded on-demand, rarely audited, rarely needed in production, and occasionally exploitable. The n_hdlc module implements an HDLC line discipline used by old serial/WAN equipment that no modern hosting server has.
What kernsec does:
dev.tty.ldisc_autoload=0 # KSEC-SCT-kernel.surface-001
This prevents automatic loading of line discipline modules in response to a TIOCSETD ioctl. Combined with the module blacklist group (modules.ldisc), the HDLC surface is simply gone. The same logic applies to the dozens of bus and peripheral modules in the modules.bus group — FireWire, Thunderbolt, old PCMCIA, joystick drivers, floppy. None of them belong on a hosting server.
Unsigned modules and kexec
lockdown=integrity (Tier 2 boot arg) activates the kernel lockdown LSM in integrity mode, which blocks:
/dev/memand/dev/kmemwrite access- Loading unsigned kernel modules
- Unsigned kexec (replacing the running kernel)
module.sig_enforce=1 (auto-skipped if DKMS modules detected) goes further and refuses to load any module without a valid kernel signature, even if lockdown isn’t active.
These don’t stop a local exploit that already has ring 0. They do close the path where an attacker who has root (but not a kernel exploit yet) uses insmod to load a malicious module or uses kexec to replace the kernel with one that has a backdoor.
What kernsec cannot do
It’s worth being explicit:
Zero-days in in-scope subsystems. If a CVE drops in the network stack, the VFS, or anything else the server actively uses, kernsec has no leverage. The module is loaded, the sysctl setting is the distro default, and the attack surface is fully available. Kernel patches are the only answer.
Exploits that don’t rely on the closed primitives. Closing userfaultfd doesn’t stop UAF exploits that use a different timing mechanism. Closing algif_aead doesn’t stop an exploit that uses a different crypto path. These settings raise the bar; they don’t raise it to infinity.
Post-exploitation. Once an attacker has ring 0, it’s largely over. lockdown=integrity and module.sig_enforce=1 create friction, but a sophisticated attacker with a kernel write primitive can bypass them. The point of kernsec is to prevent them from getting there, not to contain them afterward.
Runtime detection. We considered and explicitly dropped LKRG (Linux Kernel Runtime Guard). It’s fragile on production hosting environments — too many false positives, too much risk of breaking legitimate workloads, and its security guarantees against a sophisticated adversary are unclear. Kernsec is preventive, not detective. For detection you want something purpose-built for your threat model.
SELinux, AppArmor, and grsecurity. These operate in a different layer and are complementary. A full MAC policy closes privilege paths that kernsec doesn’t touch. But they’re also heavier operationally, and on shared hosting with hundreds of tenants and diverse workloads, getting policy right is non-trivial. Kernsec targets the things that are easy to turn off and broadly safe.
Drift detection and the monitor timer
One thing that matters as much as applying the settings is knowing when they’ve drifted. Boot args that get dropped by a grubby update. A sysctl file that gets overwritten by an admin running a hardening script they found on GitHub. A module that gets pulled in by a new package.
cfm kernsec monitor enable
This installs a systemd timer (default: daily) that runs cfm kernsec apply --check. The check compares desired state against actual running state and exits non-zero on any drift. systemctl is-failed cfm-kernsec-check becomes a monitoring signal. The journal records what drifted and when.
A hardening config that silently drifts back to baseline is arguably worse than no hardening at all — you think you’re protected and you’re not.
The honest bottom line
We’re not running SELinux, not running LKRG, not running grsecurity. We’re not going to stop a motivated attacker with a novel zero-day targeting code paths we can’t remove. Neither would most of those other tools, reliably.
What we’re doing is: closing the doors that are easy to close, removing the attack surface the server doesn’t need, raising the cost of reliable exploitation for the attacks we’ve actually seen, and watching for drift so the settings stay effective.
On a shared hosting server with hundreds of unprivileged users — some of whom will run malicious code intentionally — reducing the number of viable local privilege escalation paths is real security work. It’s not glamorous, it doesn’t produce a dashboard with a security score, but it means the next time a Copy Fail variant drops, a meaningful fraction of our fleet has the relevant surface already removed.
That’s the honest value proposition. No gods, no magic — just closing doors.
cfm kernsec is part of CFM, a Go-based server security platform for shared Linux/cPanel hosting environments. The standalone kspp.sh script from the same repository provides the same KSPP baseline profile for hosts that don’t run CFM.